Linked Lists
-
Arrays are of fixed size, which is both an advantage and a disadvantage. It’s an advantage because it means you know exactly how much space you’ll be using, but it’s a disadvantage because it means you have to allocate an entirely new array if you need more space. Arrays are stored as a single chunk of memory, which means that we have random access to all of their elements.
-
We introduced the linked list as a data structure of expandable size:

-
We called each of the elements of a linked list a node. Each node is implemented as a struct:
typedef struct node { int n; struct node* next; } node;
-
In the example above, the struct consists of an integer and a pointer to the next node. Using these pointers, we can traverse the entire linked list given only a pointer to the first node. The last node in the linked list has a NULL pointer. Adding a node to the linked list is as simple as allocating memory for it and rearranging pointers.
list-0.c
-
Although this file isn’t very complex, it’s conventional to put type definitions in a separate header file. When you include that file, you use double quotes instead of angle brackets because the file is local:
#include "list-0.h" -
Our
mainfunction is simply a menu interface for getting a command from the user:int main(void) { int c; do { // print instructions printf("\nMENU\n\n" "1 - delete\n" "2 - insert\n" "3 - search \n" "4 - traverse\n" "0 - quit\n\n"); // get command printf("Command: "); c = GetInt(); // try to execute command switch (c) { case 1: delete(); break; case 2: insert(); break; case 3: search(); break; case 4: traverse(); break; } } while (c != 0); // free list before quitting node* ptr = first; while (ptr != NULL) { node* predptr = ptr; ptr = ptr->next; free(predptr); } }
-
We have a do-while loop to prompt the user for non-negative input. Once the user provides input, we switch on it to execute one of the four different functions. Finally, we free the linked list before exiting.
Search
-
Let’s take a look at how the
searchfunction is implemented:void search(void) { // prompt user for number printf("Number to search for: "); int n = GetInt(); // get list's first node node* ptr = first; // search for number while (ptr != NULL) { if (ptr->n == n) { printf("\nFound %i!\n", n); sleep(1); break; } ptr = ptr->next; } }
-
We declare a pointer to a node called
ptrand point it to the first node in the list. To iterate through the list, we set our while condition to beptr != NULL. The last node in the linked list points to NULL, soptrwill beNULLwhen we’ve reached the end of the list. To access the integer within the node thatptrpoints to, we use the->syntax.ptr->nis equivalent to(*ptr).n. If the integer within the node is the one we’re searching for, we’re done. If not, we updateptrto be thenextpointer of the current node.
Insertion
-
Insertion into a linked list requires handling three different cases: the beginning, middle, and end of the list. In each case, we need to be careful in how we update the node pointers lest we end up orphaning part of the list.
-
To visualize insertion, we’ll bring 6 volunteers onstage. 5 of these volunteers will represent the numbers 9, 17, 22, 26, and 34 that are in our linked list and 1 volunteer will represent the
firstpointer. -
Now, we’ll request memory for a new node, bringing one more volunteer onstage. We’ll give him the number 5, which means that he belongs at the beginning of the list. If we begin by pointing
firstat this new node, then we forget where the rest of the list is. Instead, we should begin by pointing the new node’snextpointer at the first node of the list. Then we updatefirstto point to the new node. -
Again, we’ll request memory for a new node, bringing another volunteer onstage and assigning her the number 55. She belongs at the end of the list. To confirm this, we traverse the list by updating
ptrto the value ofnextfor each node. In each case, we see that 55 is greater thanptr->n, so we advance to the next node. However, ultimately, we end up withptrequal toNULLbecause 55 is greater than all of the numbers in the list. We don’t have a pointer, then, to the last node in the list, which means we can’t update it. To prevent this, we need to keep track of the node one to the left ofptr. We’ll store this in a variable calledpredptrin our sample code. When we reach the end of the list,predptrwill point to the last node in the list and we can update itsnextvalue to point to our new node. -
Another solution to this problem of keeping track of the previous node is to implement a doubly linked list. In a doubly linked list, each node has a
nextpointer to point to the next node and aprevpointer to point to the previous node. -
Once more, we’ll request memory for a new node, assigning the value 20 to our last volunteer. This time when we traverse the list, our
predptris pointing to the 17 node and ourptris pointing to the 22 node when we find thatptr->nis greater than 20. To insert 20 into the list, we point thenextpointer ofpredptrto our new node and thenextpointer of our our new node toptr. -
Linked lists are yet another example that design is very much subjective. They are not unilaterally better than arrays, but they may be more useful than arrays in certain contexts. Likewise, arrays may be more useful than linked lists in certain contexts.
Hash Tables
-
The holy grail of running time is O(1), i.e. constant time. We’ve already seen that arrays afford us constant-time lookup, so let’s return to this data structure and use it to store a list of names. Let’s assume that our array is of size 26, so we can store a name in the location corresponding to its first letter. In doing so, we also achieve constant time for insertion since we can access location
iin the array in 1 step. If we want to insert the name Alice, we index to location 0 and write it there. -
This data structure is called a hash table. The process of getting the storage location of an element is called hashing and the function that does so is called a hash function. In this case, the hash function simply takes the first letter of the name and converts it to a number.
Linear Probing
-
What problems might arise with this hash table? If we want to insert the name Aaron, we find that location 0 is already filled. We could take the approach of inserting Aaron into the next empty location, but then our running time deteriorates to linear because in the worst case, we may have to iterate through all n locations in the array to insert or search for a name. This approach is appropriately named linear probing.
Separate Chaining
-
When two elements have the same hash, there is said to be a collision in the hash table. Linear probing was our first approach to handling collisions. Another approach is separate chanining. In separate chaining, each location in the hash table stores a pointer to the first node of a linked list. When a new element needs to be stored at a location, it is simply added to the beginning of the linked list.
The Birthday Problem
-
Why worry at all about collisions? How likely is it really that they will happen? It turns out the probability of collisions is actually quite high. We can phrase this question in a slightly different way that we’ll call the Birthday Problem:
In a room of n CS50 students, what’s the probability that at least 2 students have the same birthday?
-
To answer this question, we’ll consider the opposite: what’s the probability that no 2 students have the same birthday. If there’s only 1 student in the room, then the probability that no 2 students have the same birthday is 1. If there are 2 students in the room, then there are 364 possible birthdays out of 365 which the second student could have that would be different from the first student’s. Thus, the probability that no 2 students have the same birthday in a room of 2 is 364 ⁄ 365. The probability that no 2 students have the same birthday in a room of 3 is 363 ⁄ 365. And so on. To get the total probability, we multiple all of these probabilities together. You can see this math here, courtesy of Wikipedia:
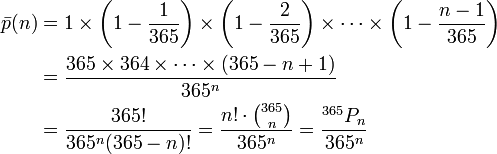
-
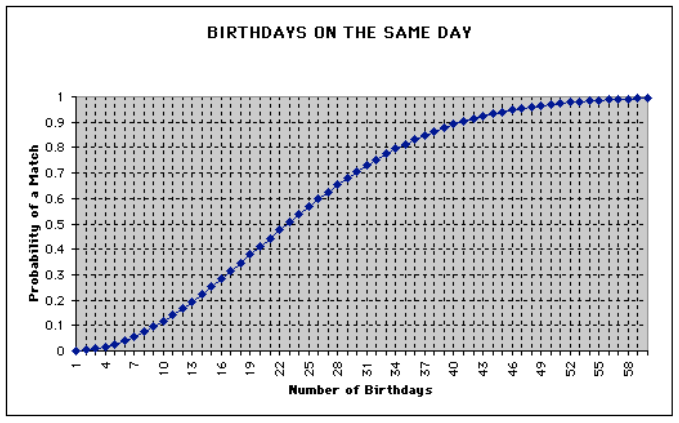
This is much easier to interpret in the form of a graph, however:
-
Notice that the probability is already 0.5 when there are only 22 students in the room. By the time we consider the case where there are 58 students in the room, the probability is almost 1. The implication for hash tables is that there are going to be collisions.
-
What is the worst-case running time of search in a hash table that uses separate chaining? In the worst case, we’re going to have to traverse the entire linked list at any hash table location. If we consider the number of locations in our hash table to be m, then the lookup time for a hash table that uses separate chaining is O(n ⁄ m). m is a constant, though, so the lookup time is really just O(n). In the real world, however, O(n ⁄ m) can be much faster than O(n).
-
What is the worst-case running time of insertion in a hash table that uses separate chaining? It’s actually O(1) if we always insert to the beginning of the linked list at each hash table location.
Tries
-
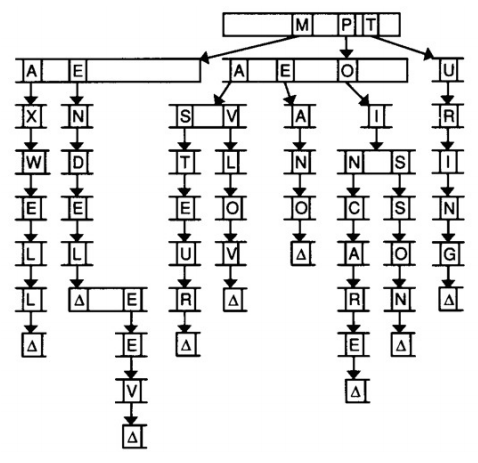
One last data structure we’ll discuss is a trie. The word “trie” comes from the word “retrieval,” but is usually pronounced like “try.” For our purposes, the nodes in a trie are arrays. We might use a trie to store a dictionary of names of famous scientists, as this diagram suggests:
-
In this trie, each index in the array stands for a letter of the alphabet. Each of those indices also points to another array of letters. The Δ symbol denotes the end of a name. We have to keep track of where words end so that if one word actually contains another word (e.g. Mendeleev and Mendel), we know that both words exist. In code, the Δ symbol could be a Boolean flag in each node:
typedef struct node { bool word; struct node* children[27]; } node;
-
One advantage of a trie is that insertion and search times are unaffected by the number of elements already stored. If there are n elements stored in the trie and you want to insert the value Alice, it still takes just 5 steps, one for each letter. This runtime we might express as O(k), where k is the length of the longest possible word. But k is a constant, so we’re actually just talking about O(1), or constant-time insertion and lookup.
-
Although it may seem like a trie is the holy grail of data structures, it may not perform better than a hash table in certain contexts. Choosing between a hash table and a trie is one of many design decisions you’ll have to make for Problem Set 6.
Teaser
-
Before long, we’ll transition to talking about web development, including HTML, PHP, and JavaScript. As a brief teaser, enjoy this trailer to Warriors of the Net.